
温馨提醒
如果文章内容或图片资源失效,请留言反馈,我们会及时处理,谢谢
本文最后更新于2025年5月7日,已超过 180天没有更新
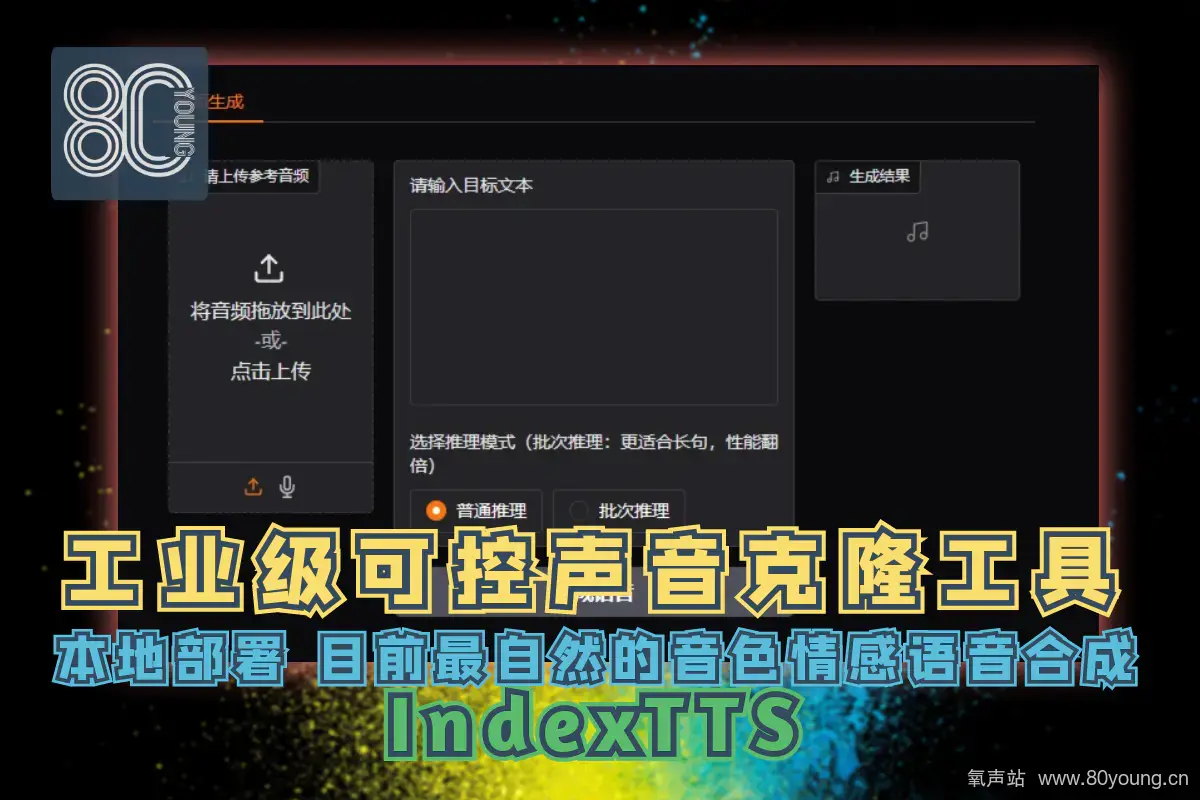
近年来,基于大型语言模型(LLM)的文语转换(TTS)系统凭借其高自然度和强大的零样本语音克隆能力逐渐成为业界主流。我们推出了IndexTTS系统,该系统主要基于XTTS和Tortoise模型,并增加了一些新颖的改进,具体来说,针对中文场景,我们采用了汉字和拼音相结合的混合建模方法,使多音字和长尾字的发音可控。我们还对矢量量化(VQ)和有限标量量化(FSQ)对声学语音token的码本利用率进行了对比分析。为了进一步提升语音克隆的效果和稳定性,我们引入了基于一致性的语音条件编码器,并用BigVGAN2替换了音码解码器。与XTTS相比,它在自然度、内容一致性和零样本语音克隆方面均取得了显著的提升。与开源中流行的语音合成系统(例如 Fish-Speech、CosyVoice2、FireRedTTS 和 F5-TTS)相比,IndexTTS 的训练过程相对简单,使用方式更可控,推理速度更快,性能也远超这些系统。
在中文场景下,IndexTTS引入了汉字和拼音混合建模的方法,可以快速纠正发音错误的汉字。IndexTTS集成了顺应性条件编码器和基于 BigVGAN2 的语音解码器,从而提升了训练稳定性、语音音色相似度和音质。
使用教程
安装及使用方式
登录可见隐藏内容
声明:“80young声”为非营利性个人网站,所有软件来自于互联网,版权属原著所有,如有需要请购买正版,资源仅供学习交流使用,请勿用于商业用途!并请于下载后24小时内删除,谢谢!如有侵权,敬请来信联系我们,我们立刻删除。
本文链接:80Young声(氧声站)https://www.80young.cn/710.html
许可协议:《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
本文链接:80Young声(氧声站)https://www.80young.cn/710.html
许可协议:《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权


